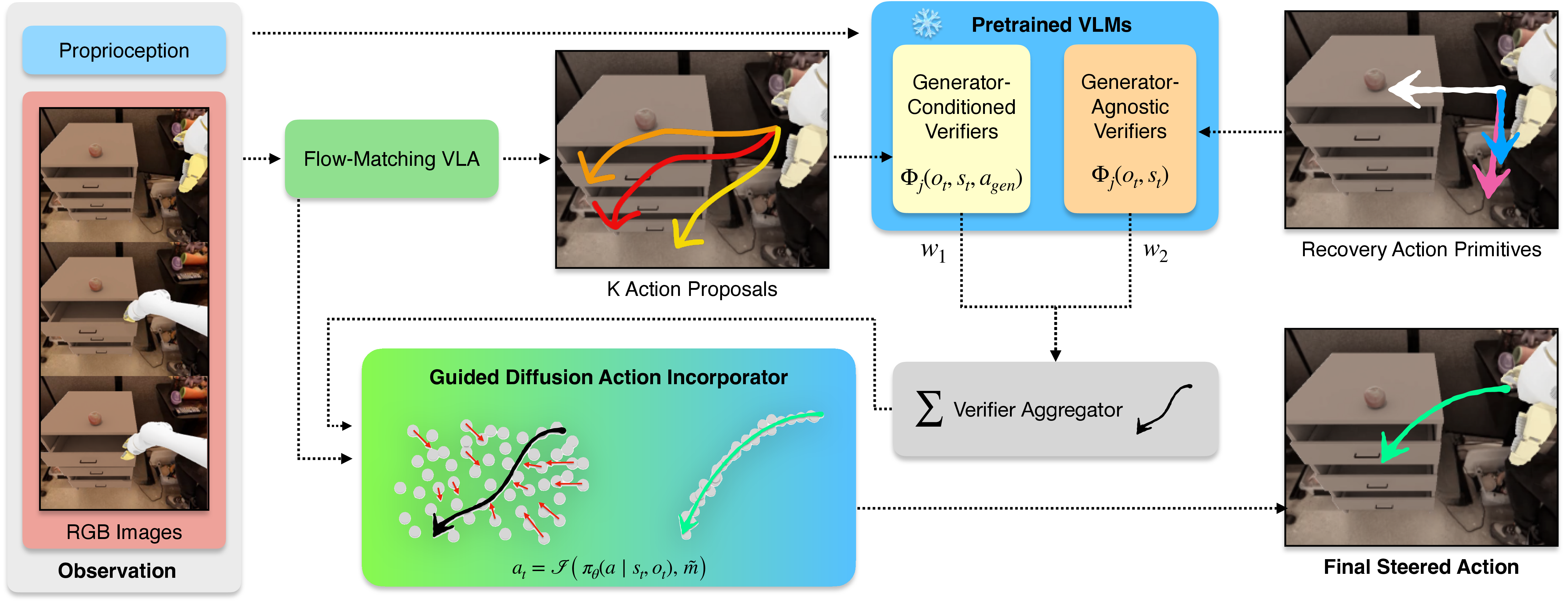
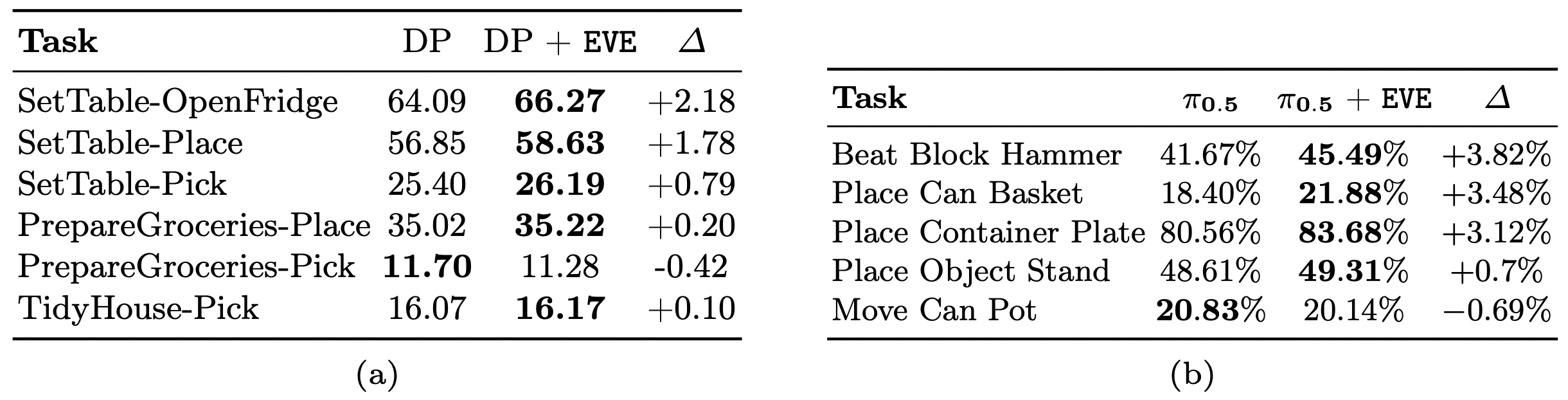
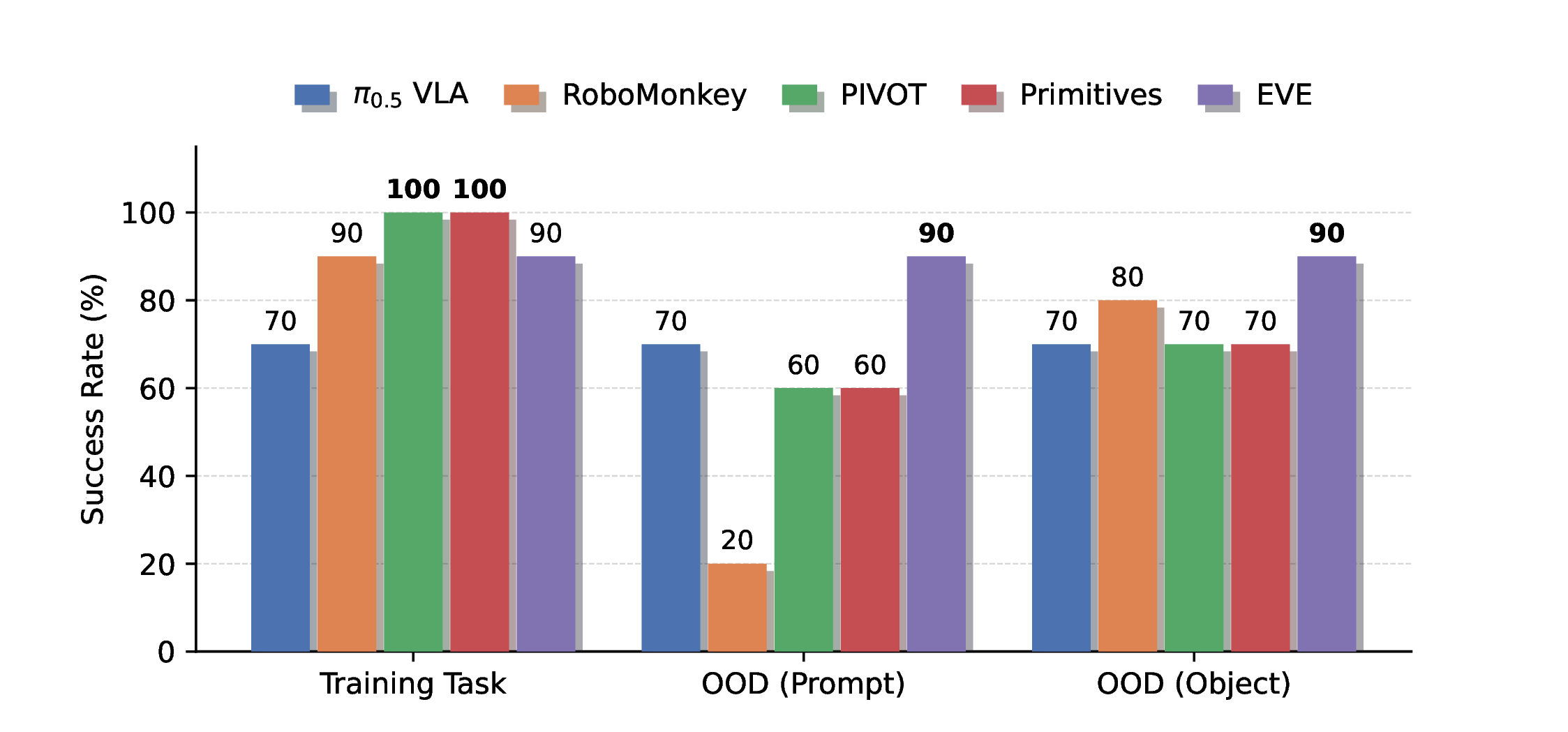
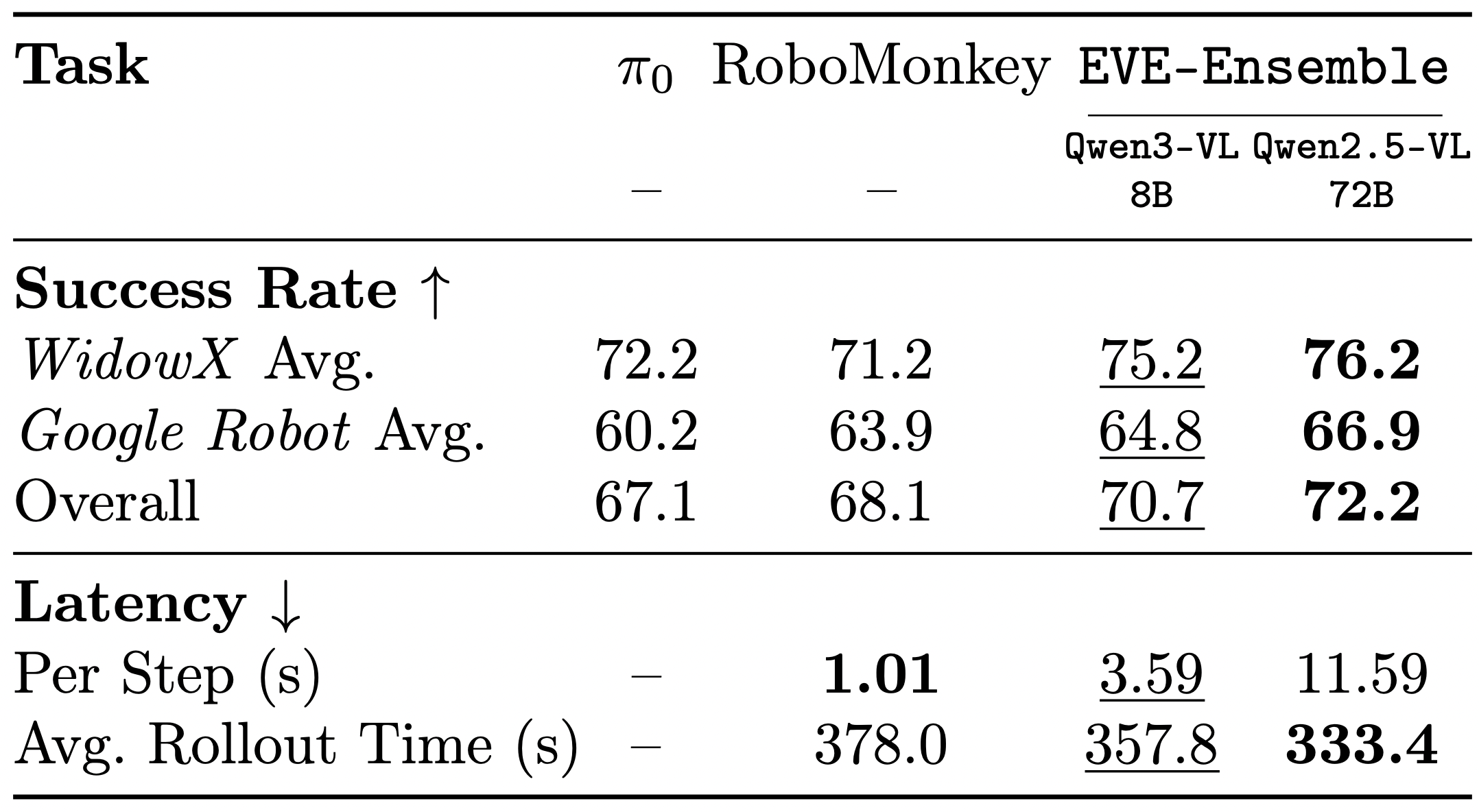
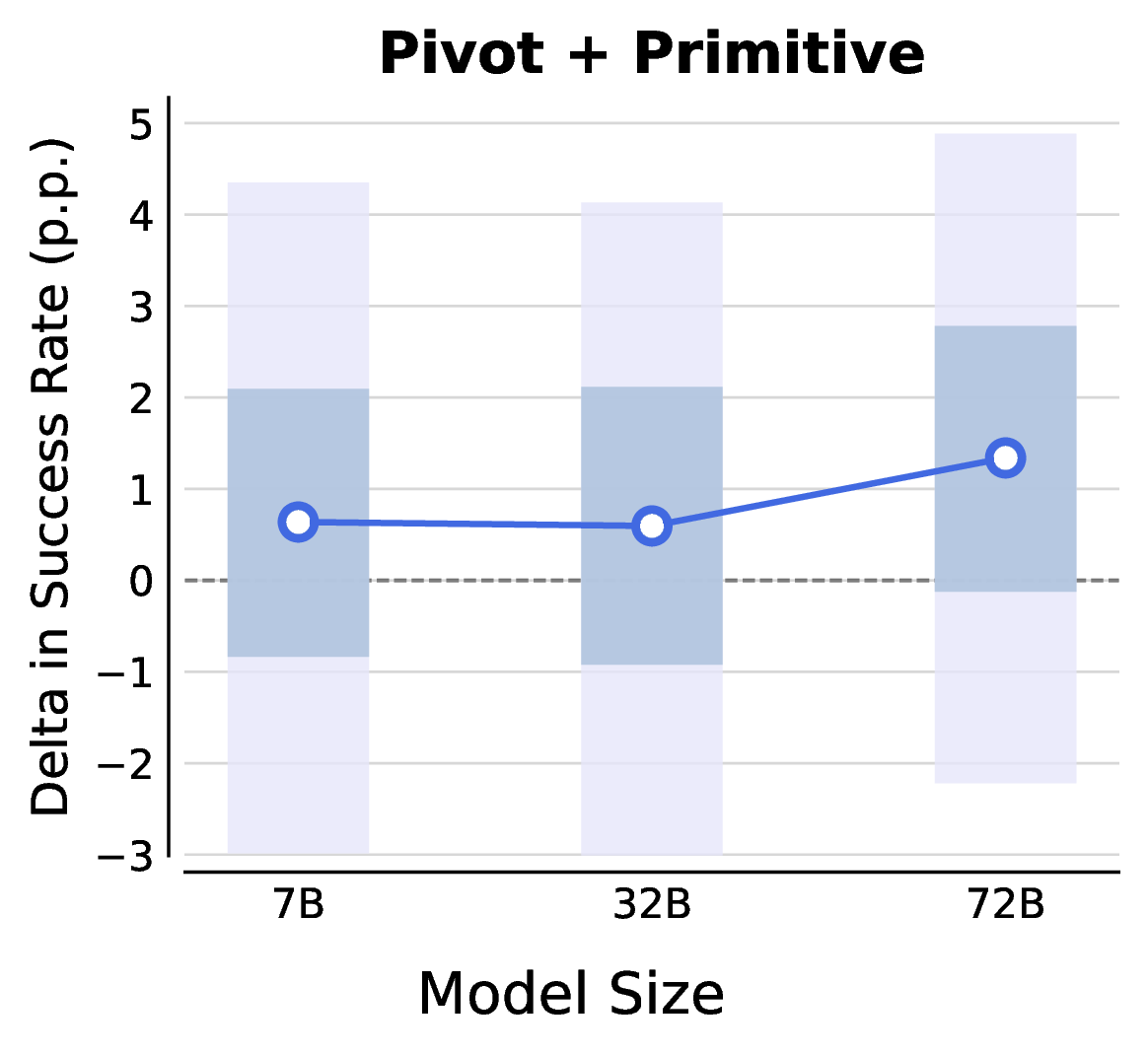
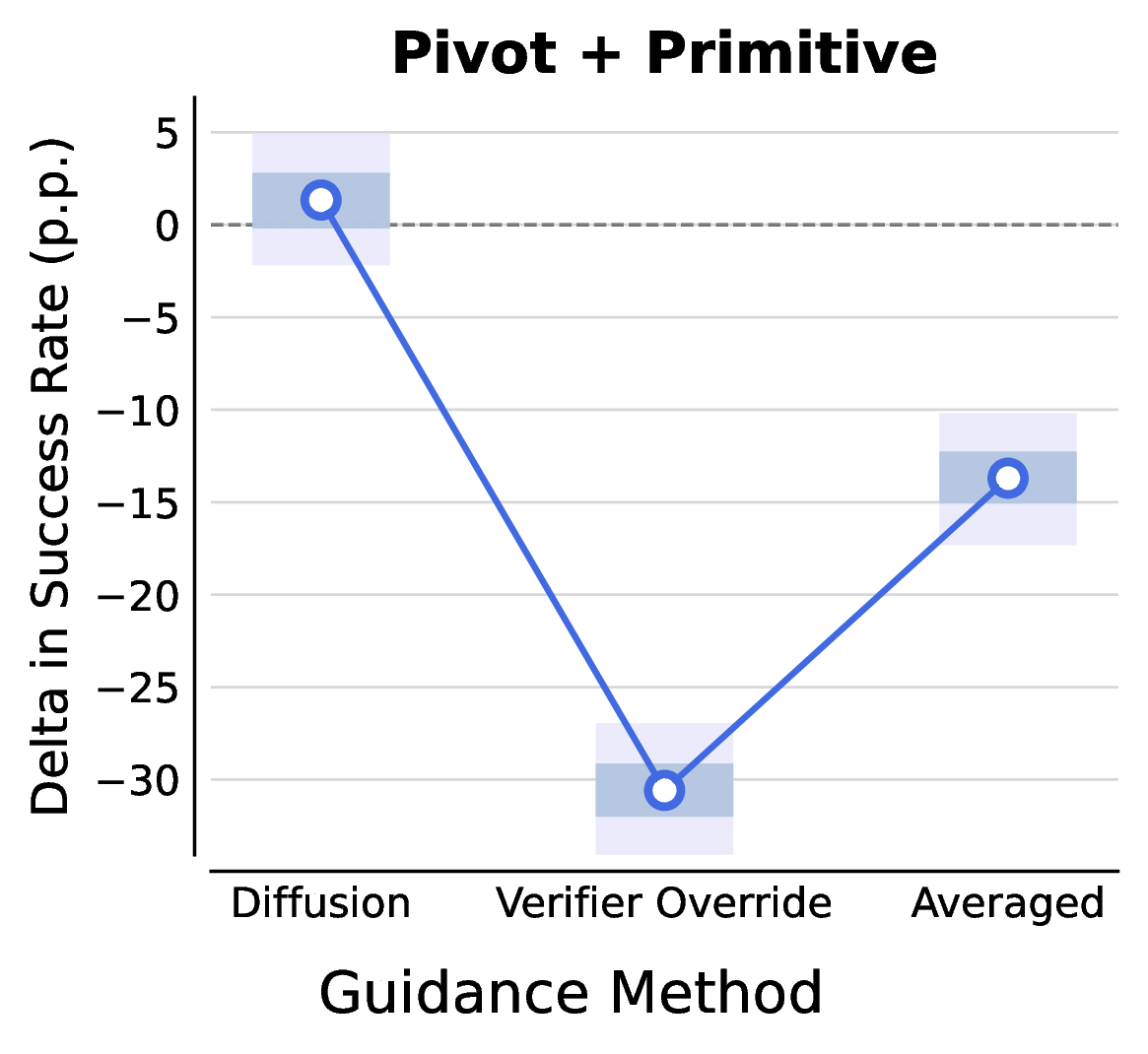
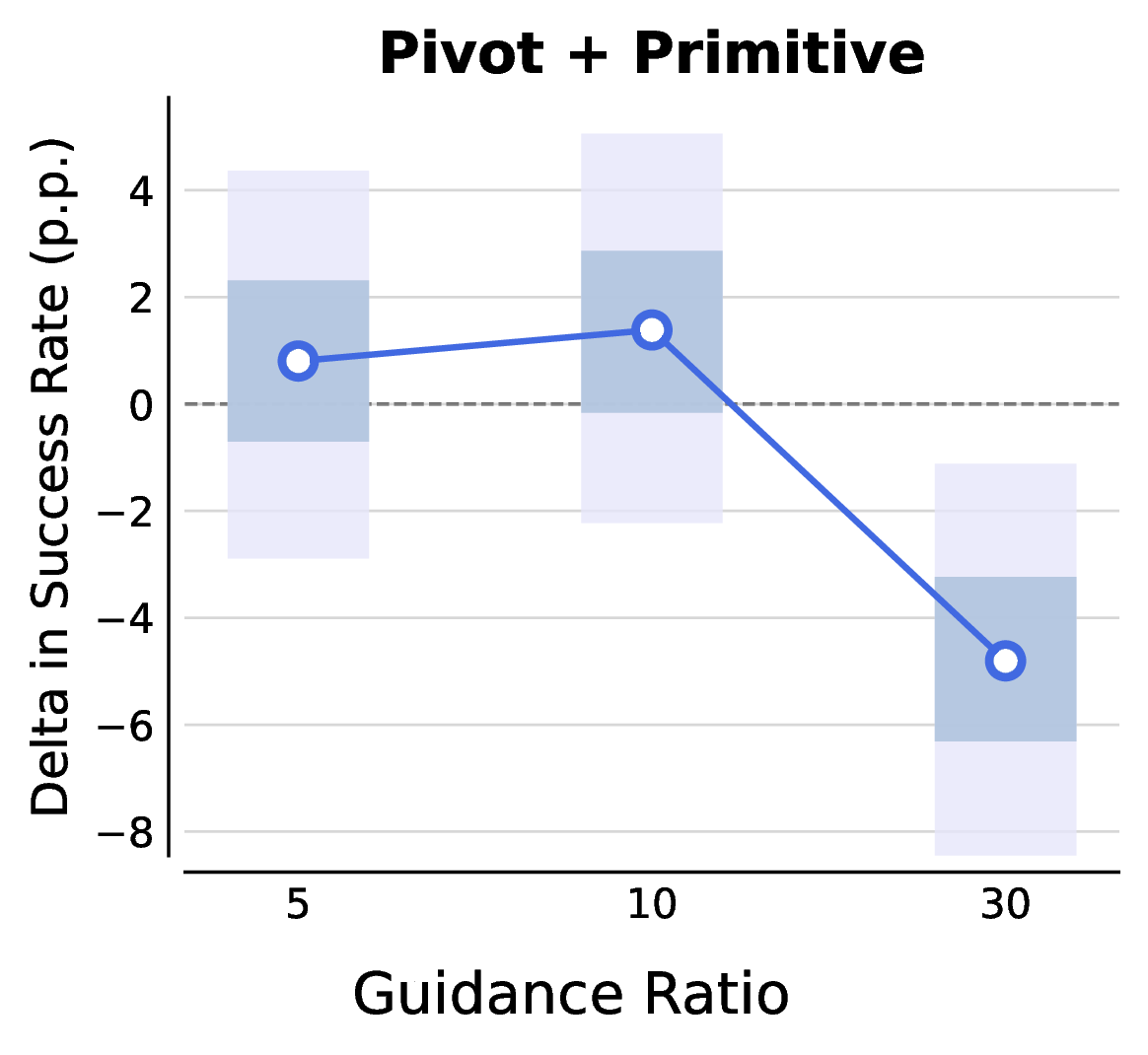
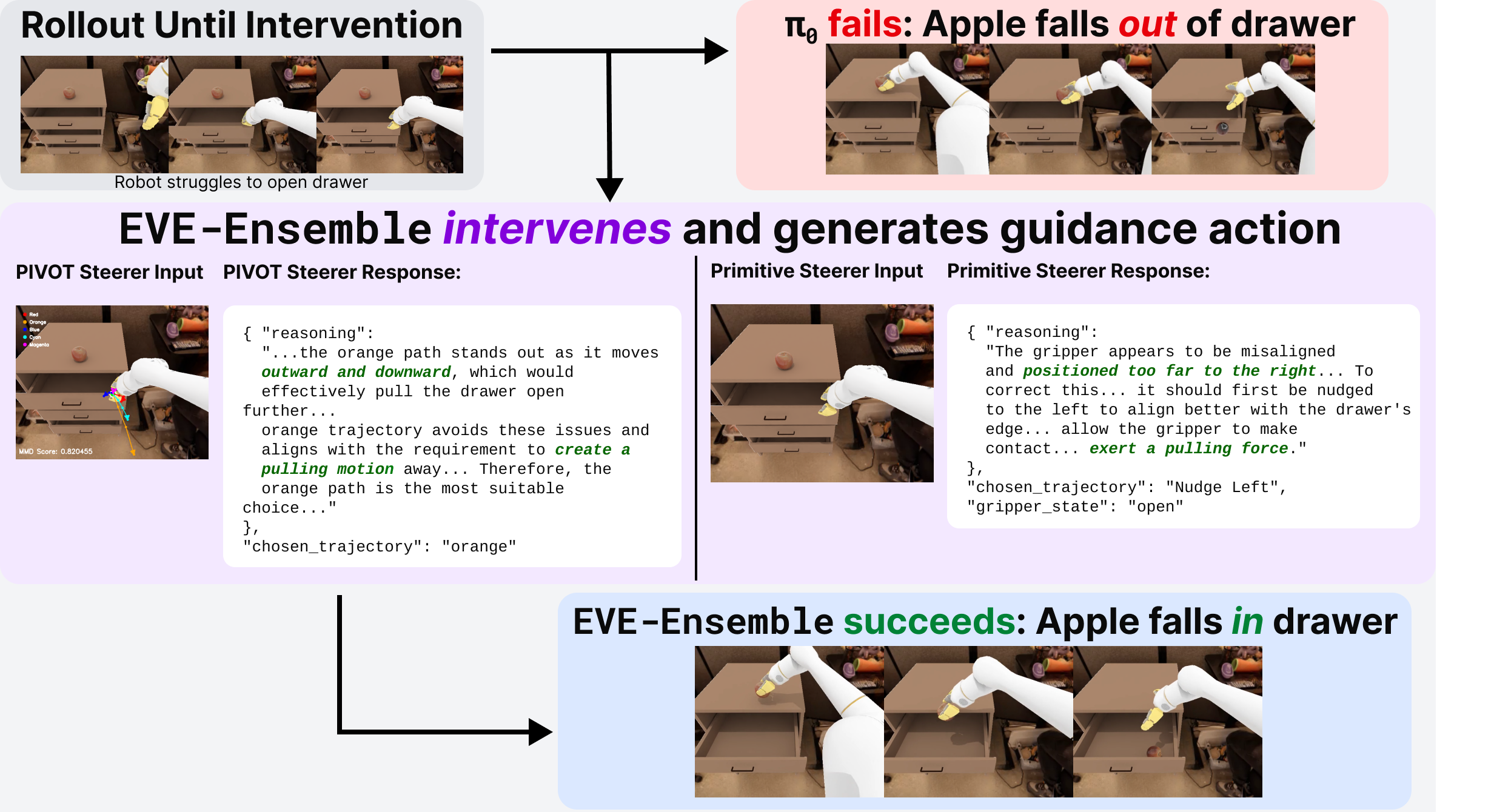
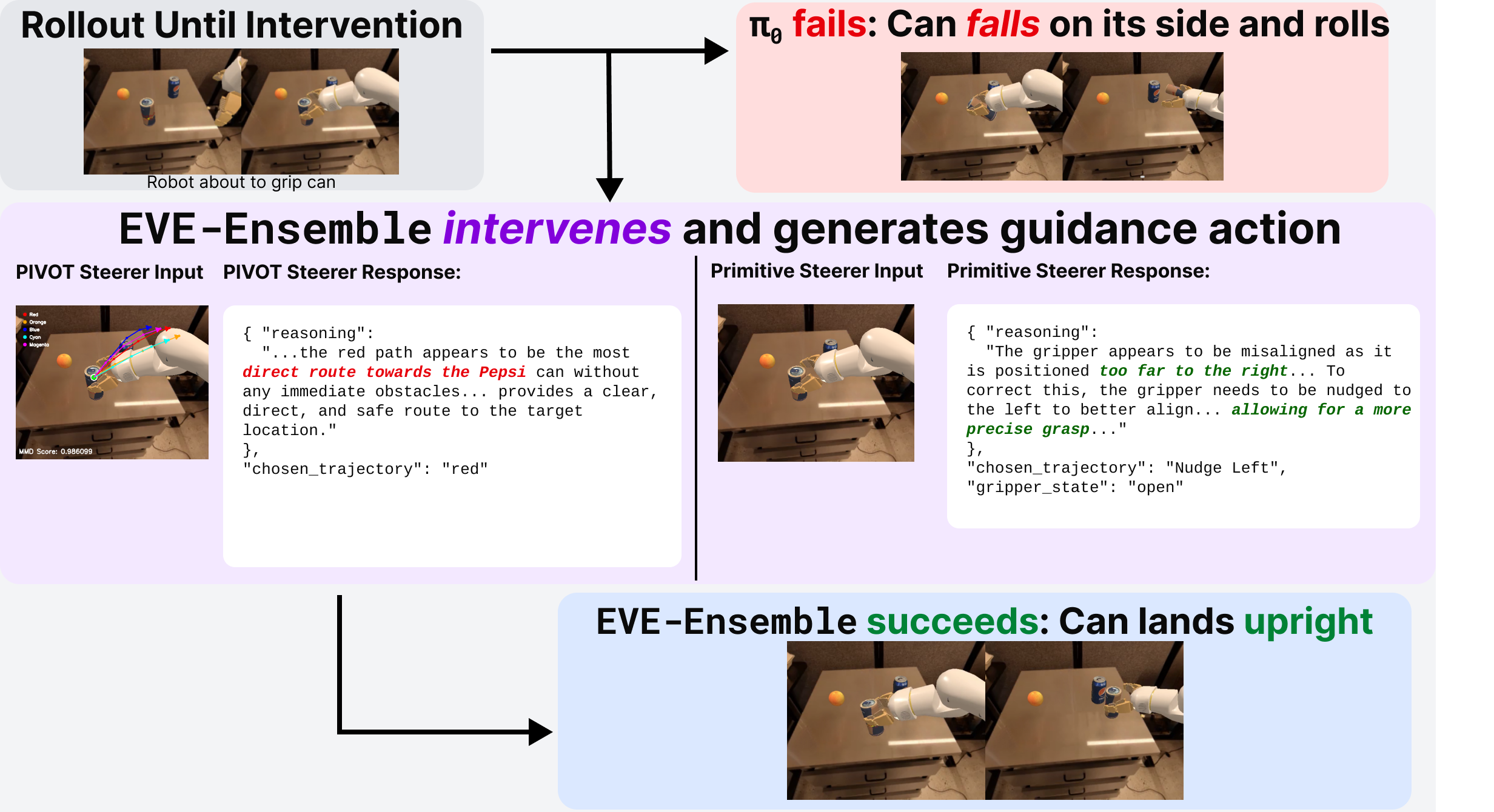
EVE: A Generator-Verifier System for Generative Policies
EVE: A Generator-Verifier System for Generative Policies
Under Review
Lightning Talk✨ at ICRA Semantics for Reliable Robot Autonomy Workshop, 2026 (Slides)
Poster Presentation at ICRA Data to Decisions: VLA Pipelines for Real Robots Workshop, 2026